- Jan 09, 2026
Share this post on:
Did you know that the global retrieval augmented generation market size is estimated to reach USD 11.0 billion by 2030, growing at a CAGR of 49.1%? This growth reflects the revolutionary role RAG plays in enhancing AI accuracy, contextual understanding, and real-time data integration across industries like healthcare, finance, retail, and more. But why is RAG-powered AI becoming so important? How can enterprises reduce AI hallucinations and boost response relevance? What does it take to build a robust RAG application that integrates proprietary and external data sources? How should businesses balance the costs and complexity of developing these next-generation AI systems? What are the strategic considerations for choosing the right development partner to ensure success with RAG-powered applications?
As AI continues to reshape how we interact with information, Retrieval-Augmented Generation (RAG) has emerged as a groundbreaking framework for developing intelligent, reliable, and domain-specific applications. Traditional large language models (LLMs) like GPT-4 are powerful, but they are limited by static training data and hallucination risks. RAG addresses these issues by combining real-time information retrieval with natural language generation, resulting in apps that are not only smart but also context-aware and factually accurate.
Whether you're building a legal assistant, a medical knowledge base, or a customer service chatbot, RAG can unlock a new level of performance.
Key Takeaways:
Retrieval-Augmented Generation applications combine the prowess of information retrieval with large language models (LLMs).
Choose a development partner who has expertise in RAG and AI Technologies.
Developing a RAG-powered application requires a thoughtful approach, starting from data preparation and embedding to seamless LLM integration.
While costs vary according to complexity and scale, businesses that invest in RAG benefit from improved AI accuracy and context relevancy.
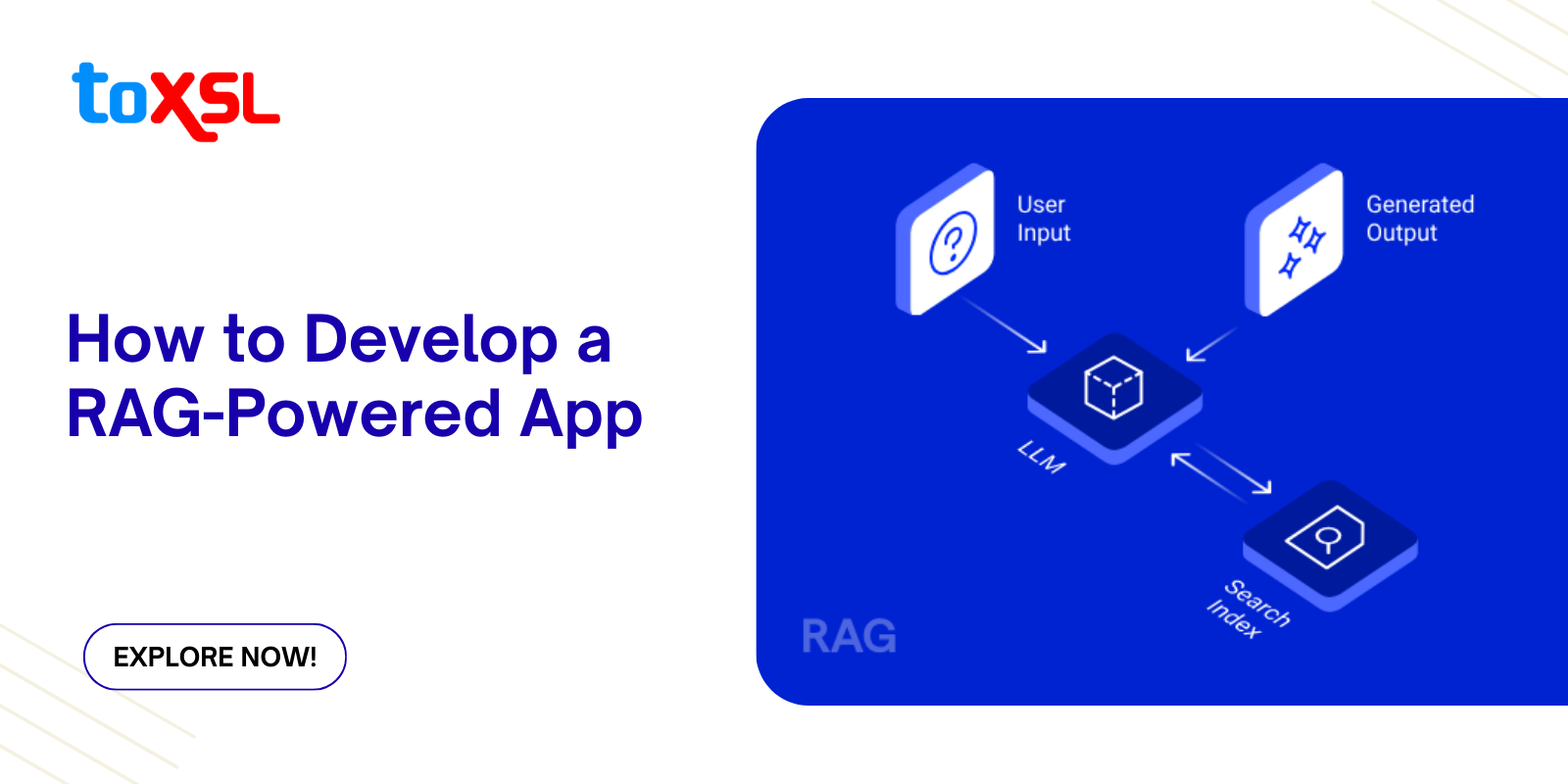
Working Process of RAG-powered Applications
Retrieval-Augmented Generation applications combine the prowess of information retrieval with large language models (LLMs), enabling AI to generate accurate, contextually relevant responses grounded in real-world data. At a high level, the workflow includes:
Data Ingestion and Preparation: Raw data from diverse sources (documents, databases, websites) is cleaned, parsed, and split into manageable chunks.
Vector Embedding and Indexing: Each chunk is converted into numerical vector embeddings representing semantic meaning and stored in a vector database for efficient similarity search.
Query Embedding and Retrieval: User queries are embedded and matched against the index to fetch relevant data snippets.
Augmented Generation: The retrieved information is combined with the query and fed to a Large Language Model (LLM), which generates enriched, precise answers.
Deployment and Monitoring: The application interface (e.g., chatbot, search engine) is deployed with continuous monitoring to maintain performance and update data.
This process ensures users get not only fluent AI text but also accuracy rooted in factual data, overcoming traditional LLM hallucination issues.
Steps to Develop a RAG-powered App
The core steps to develop a RAG-powered app can be summed up as a structured pipeline combining data ingestion, retrieval, augmentation, and generation, ensuring accurate and context-aware AI responses. Based on authoritative resources, the typical steps include:
Receive User Query or Prompt: The system starts by taking in a user’s input—a question, a request for information, or content.
Search Relevant Source Information: The query is transformed into a vector embedding (numerical representation) and used to search an external knowledge base or vector database for relevant documents or data pieces.
Retrieve Relevant Information: The system fetches the most pertinent data chunks/documents that match the user query's semantic meaning, ensuring the raw material for generation is accurate and credible.
Augment the Query with Retrieved Context: The original user prompt is enriched by appending the retrieved relevant information, forming an augmented prompt.
Generate Response Using a LLM: The augmented prompt is fed into an LLM (such as OpenAI GPT), which synthesizes an answer or output that is both contextually accurate and informative.
Deliver the Enhanced Response to the User: The final generated content is returned to the user, responding with higher accuracy and relevance than would be possible with generative models alone.
This high-level flow reflects the core RAG mechanism: retrieval from external data sources combined with generative AI to enhance response quality.
Additionally, the development process for building such an app typically follows these phases:
Data Ingestion and Preparation: Collect, clean, parse, and chunk data (documents, databases, web content), then convert chunks into vector embeddings using embedding models (OpenAI embeddings, open-source alternatives).
Indexing and Storage: Store embeddings in a vector database to enable fast similarity search and scalable retrieval.
Retrieval Mechanism Implementation: Develop a system that converts user queries to embeddings and performs a similarity search to retrieve relevant context. Enhance retrieval with query rewriting, hybrid searches, and reranking.
Integration with LLMs: Design a prompt engineering that combines user input and retrieved information, then call LLM APIs to generate responses.
Application and UI Development: Build frontend components (chatbots, Q&A tools), backend APIs, and orchestration (using frameworks like LangChain or LlamaIndex) to manage the full query–retrieve–generate pipeline.
Testing, Deployment, and Monitoring: Test for accuracy, performance, and UX; deploy on cloud or on-premises systems; monitor and update data and models regularly to maintain response quality.
Read More: Traditional RAG vs. Agentic RAG: How to Improve AI Agents Work Smarter
Cost to Develop a RAG-powered Application
The cost to develop a RAG-powered (Retrieval-Augmented Generation) application can vary widely depending on several factors, including the complexity of the use case, team size, infrastructure choices, and deployment environment. Here's a breakdown table showing the approximate costs involved in building a RAG application:
Category | Component | Estimated Cost Range (USD) | Notes |
|---|---|---|---|
Development | Backend Development | $10,000 – $50,000 | Depends on architecture, APIs, and use case complexity |
Frontend Development | $5,000 – $30,000 | Varies based on UI/UX, web or mobile platform | |
RAG Pipeline Integration | $10,000 – $40,000 | Integrating retrieval (e.g., vector DB) and generation (LLM) | |
Infrastructure | Vector Database (e.g., Pinecone, FAISS) | $100 – $3,000/month | Pricing depends on data volume and query frequency |
Cloud Hosting (AWS/GCP/Azure) | $200 – $5,000/month | Includes compute (for LLM + embedding) and storage | |
AI Models | OpenAI/GPT API usage | $100 – $10,000/month | Based on token usage and user volume |
Embedding Models (e.g., OpenAI, Cohere) | $50 – $2,000/month | Embedding costs scale with content ingestion | |
Data | Data Collection & Cleaning | $1,000 – $15,000 | Costs for sourcing and preparing domain-specific documents |
Document Chunking & Indexing | $500 – $5,000 | May involve custom logic or tooling | |
Security & QA | Authentication, Rate Limiting, etc. | $2,000 – $10,000 | Especially important in enterprise-grade apps |
Testing & QA | $2,000 – $8,000 | Includes manual & automated testing | |
Maintenance | Monitoring & Updates | $1,000 – $3,000/month | Includes model updates, data refresh, infra scaling |
How to Hire the Best RAG-powered Application Development Partner
To hire the best partner for developing a Retrieval-Augmented Generation (RAG)-powered application, focus on these key criteria:
1. Expertise in RAG and AI Technologies: Choose a development firm with demonstrated experience building RAG systems, including strong skills in vector databases (e.g., Pinecone, Weaviate), embedding models, retrieval algorithms, and large language model (LLM) integration (OpenAI GPT, Anthropic). They should also be familiar with orchestration frameworks like LangChain or LlamaIndex.
2. Industry and Domain Knowledge: Ensure the partner understands your specific industry, data types, and compliance requirements. Familiarity with your domain helps tailor the solution to your business needs and ensures more relevant, context-aware AI responses.
3. Agile Development Process: The partner should adopt an iterative approach that allows for quick prototyping, feedback incorporation, and continuous delivery, ensuring the final RAG app aligns tightly with your expectations and evolving goals.
4. Transparent Pricing: Look for clear cost estimates, timelines, deliverables, and post-deployment support options. Transparent contracts minimize surprises and keep the project on track financially and schedule-wise.
5. Strong Portfolio and References: Prioritize partners with case studies or client testimonials highlighting successful RAG app deployments, scalability handling, and demonstrated ROI improvements.
6. Ability to Provide Proof-of-Concept or Pilot: A partner willing to develop a pilot version lets you validate their technical approach and understand the solution’s value before full-scale investment.
Conclusion
Retrieval-Augmented Generation (RAG) is transforming AI by grounding language models in real-time, relevant data. Developing a RAG-powered application requires a thoughtful approach, starting from data preparation and embedding, through advanced retrieval techniques, to seamless LLM integration and user-friendly application development. While costs vary according to complexity and scale, businesses that invest in RAG benefit from dramatically improved AI accuracy and context relevancy, enhancing user trust and operational efficiency. ToXSL Technologies, an experienced development partner, ensures your RAG app is robust, scalable, and aligned with your strategic goals. Embrace RAG technology to unlock the next frontier of AI-driven applications tailored to your enterprise's unique knowledge ecosystem.
Frequently Asked Questions
1. What is a RAG-powered app and how does it work?
A RAG-powered app combines retrieval and generation. It first retrieves relevant information from a knowledge base and then uses a large language model (LLM) to generate accurate, context-aware responses based on that information. This ensures answers are both up-to-date and domain-specific.
2. What are the main components needed to build a RAG app?
The key components are:
• Knowledge base (documents, databases, APIs)
• Vector database to store embeddings for efficient retrieval
• Generative model (GPT, LLaMA, Falcon, etc.)
• Integration layer to combine retrieval and generation into responses
• User interface to interact with users
3. How do I ensure the answers from my RAG app are reliable?
Reliability comes from grounding the generative model in retrieved content. Use high-quality, up-to-date data, limit the context to relevant documents, provide source references, and incorporate user feedback for continuous improvement.
4. Can I build a RAG app using open-source tools?
Yes! Open-source LLMs like LLaMA, MPT, or Falcon can replace GPT, and vector databases like FAISS, Weaviate, or Pinecone can handle document embeddings and retrieval. This allows full on-premises deployment if privacy or cost is a concern.
5. What are the common challenges when developing a RAG app?
Some challenges include:
• Managing large knowledge bases efficiently
• Avoiding LLM hallucinations
• Handling context window limitations for long documents
• Keeping the knowledge base up-to-date
• Controlling latency and inference costs









